返回
英特尔Panther Lake架构解析:下一代笔记本期待住了!
时间:2025-11-15 15:42:58
代号PantherLake的英特尔酷睿Ultra处理器(第三代)是首款基于Intel18A制程工艺打造的客户端SoC,在此基础上具备前代高性能、高能效优势。英特尔表示,在高能效前提下,PantherLake相比上代带来了50%的CPU、GPU性能提升,且平台对比LunarLake功耗降低最多10%,对比ArrowLake功耗降低可达40%,这自然让我们对于下一代笔记本更加期待了。毕竟无论是LunarLake打破x86平台续航刻板印象的出色表现,还是摆脱“卷功耗”的ArrowLake都给“古井无波”的笔记本行业带来了新活力,让OEM打造了更多有差异化的产品。

就在上周,英特尔也正式公布了下一代酷睿Ultra处理器PantherLake架构与技术细节,接下来天极网就为大家送上详细解读。
需要指出的是,目前英特尔只解禁了PantherLake的架构设计以及技术特性,至于具体的SKU、性能实测等内容需要等到产品正式发布时揭晓。不过大家也不用担心等太久,根据英特尔发布的消息,PantherLake将于今年开始进入大规模量产,首款SKU预计在年底前出货,并于2026年1月实现广泛的市场供应。不出意外的话,在CES2026前后就能看到搭载PantherLake的新一代笔记本发布了。
RibbonFET全环绕栅极晶体管为英特尔全新晶体管架构,采用了4条垂直堆叠的纳米带(NanoRibbons)结构,让栅极能够从四面包电流通道完全环抱起来,可增强晶体管开关控制、响应速度,并显著抑制漏电。同时,RibbonFET相比传统晶体管结构能够带来更好的可扩展性与设计灵活性,能够实现在同一个工艺平台上围绕高性能、低功耗等不同优化方向设计多种晶体管规格。

PowerVia背部供电简单理解是将以往位于晶圆正面的供电电路下沉到背面,在正面只保留信号互连部分,由此将标准单元利用率和晶体管密度提升可达10%,将压降(IRDrop)减少多达30%,将芯片运行效率最高提升6%。

英特尔表示,凭借释放晶体管潜能的RibbonFET和扫清供电障碍的PowerVia两项技术,Intel18A的密度和能效同步提升。对比Intel3,Intel18A工艺在相同功耗下每瓦性能提升超过15%;相同性能下功耗降低可以达到25%。与此同时,Intel18A还将芯片密度提升了30%,意味着在更小的芯片尺寸,能够以更低的能耗发挥更强大的性能。

Intel18A早在2024年第三季度投入试产,目前在美国亚利桑那州、俄勒冈州两地工厂开始生产,预计在今年第四季度大规模量产。同时英特尔表示,Intel18A的良品率相当或高于英特尔在过去十五年推出的制程节点。
除了制程工艺,封装方面,PantherLake采用了成熟的Foveros-S2.5D,结合EMIB将不同模块堆叠封装在基础模块上,进而在兼顾能效的前提下,提供更好的可扩展性,实现芯片的灵活定制、成本可控。

不同于MeteorLake、LunarLake,在PantherLake模块化设计布局上又有调整,包括计算模块、图形模块、平台控制模块,另外根据芯片规格会配备不同数量的填充模块。其中,计算模块包括CPU(性能核、能效核、低功耗能效核)、NPU、IPU、媒体和显示引擎等;图形模块为GPU;平台控制模块则包括Wi-Fi、蓝牙、雷电等。
目前英特尔介绍了PantherLake系列的三种芯片设计,CPU、GPU、内存、PCIe均为不同规格,由此在面向不同应用场景时可以有更适合的产品来支撑。需要指出的是,制程工艺方面,计算模块均为Intel18A,图形模块为Intel3与台积电N3E混用,平台控制器模块都是台积电N6。
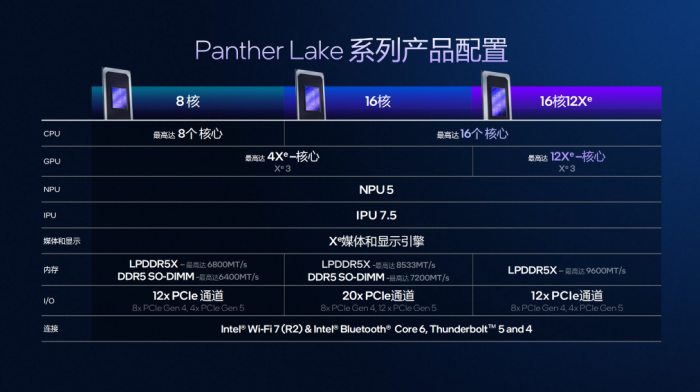
从芯片设计的差异也可以看出,PantherLake的可扩展性、灵活性优势,这将有利于OEM根据不同产品形态、价格、定位来打造SKU。只是,也希望不要给消费者在选购时出难题。

接下来就是大家关注的重点了,PantherLake的CPU、GPU、NPU等核芯究竟有哪些升级。文章比较长,分为以下几个部分,大家可以直接下滑到自己想看的内容。

PantherLake的CPU设计又回归了性能核、能效核、低功耗能效核的组合,并且升级了架构——性能核代号为CougarCove,能效核与低功耗能效核代号为Darkmont,均围绕Intel18A工艺进行设计和优化。英特尔表示,PantherLake混合核心策略为,性能核提升单线程性能核吞吐量,能效核提升多线程性能核并行度,低功耗能效核则提高效率。

CougarCove拥有18个执行端口,带来了PPA(性能功耗与面积)优化、内存消歧、16.67MHz精确频率调节、更广泛的调度(分配、重命名与撤出)、增强的分支预测、升级的TLB、拆分乱序引擎等特性。对比LunarLake的LionCove,CougarCove带来了50%的L3缓存提升,达到18MB(与能效核共享)。此外,每个核心拥有192KB一级指令缓存、48KB一级数据缓存,最高3MB二级缓存。

英特尔为CougarCove引入基于AI的电源管理,在用户多样化、复杂的使用场景中更灵活地调配内部硬件资源,保证核心性能发挥,并避免不必要的资源浪费。在提高能效方面,16.67MHz的精准时间间隔让核心实现更精细的性能与能效调控,从而提供更快速的响应和更精确的核心性能与功耗管理。
这里介绍三个亮点——内存消歧、TLB、分支预测。
内存消歧能精准预测CPU处理内存读写操作时哪些可以并行执行,哪些存在真实依赖。一旦预测错误或检测到实际冲突,内存消歧能以极快的速度进行恢复(Recovery),确保程序的正确性。由此在保证稳定可靠的前提下,提升CPU与内存之间带宽的利用率。相比LionCove,CougarCove的内存消歧性能更可靠、预测更准确、恢复更快速。

TLB本质上是CPU内部虚拟地址到物理地址的映射缓存,在混合型工作负载中尤其重要,能够避免CPU频繁访问系统内存进行耗时的页表遍历,而是将常用的地址映射预先存储,实现快速查找,进而加速内存访问,在复杂场景下优化性能。凭借Intel18A制程工艺,CougarCove的TLB增加了50%,面对复杂任务时体验更出色。
分支预测的作用是判断成语分支的走向,将预测结果反馈给CPU,并“提前准备”,是影响处理器性能的关键因素之一。PantherLake的分支预测延续了LunarLake的BPU方案,并进行优化来提高效率。英特尔表示,PantherLake的分支预测相比上代进一步提升了准确性、大幅降低了延迟,从而让CPU能够用更少的时间完成预测和修正,将更多资源聚焦于任务处理,为用户带来CPU性能提升。

Darkmont拥有26个调度端口,共享4MBL2缓存(低功耗能效也有4MBL2缓存),对比上代提升,带宽为128bit。支持增强预测、内存消歧、增强深度队列、动态预取器控制、提升AI吞吐量、Nanocode(比传统微代码更底层的微操作指令)性能提升等特性。
其中动态预取器控制的核心作用是预测CPU即将需要的数据和指令,并提前将其从内存加载到缓存中,以确保执行单元能够持续高效工作,避免因等待数据而产生的空闲。而动态体现在,Darkmont的预取器能够根据当前的工作负载类型和实时变化,智能地调整预取策略。这不仅能最大限度地保持执行单元的繁忙状态,提升性能,还能在某些场景下,通过优化预取行为,有效降低不必要的功耗。

Nanocode性能提升指的是Darkmont能够覆盖多应用场景,进行精细到前端硬件执行小单元的控制,进一步提高硬件资源的利用效率,更好地发挥能效核性能与低功耗优势。
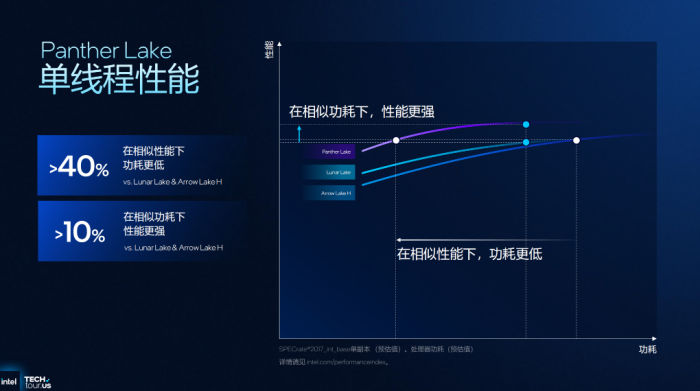
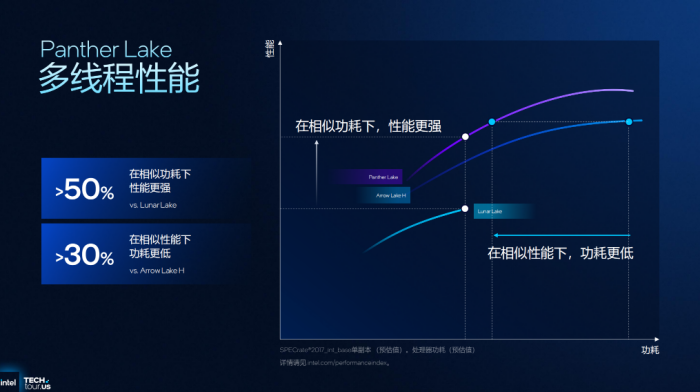
除了核心性能与能效提升,伴随着性能核、能效核一同成长的还少不了英特尔硬件线代酷睿发布后英特尔在优化平台能效方面持续迭代的特性之一。简言之,调度器就像是一个“指挥台”能够智能判断负载类型,交由更合适的核心执行或者判断负载的优先级。
在PantherLake中,英特尔进一步升级了硬件线程调度器的分类模型和输入,让其能够根据PantherLake核心特性完成分类并向系统提供反馈。这背后的调整包括优化分类模型、改善电源管理输入、扩大“繁忙”用例覆盖范围、实现跨性能核、能效核、低功耗能效核的高度并行等等。同时,还设置了操作系统隔离区,结合负载以效率、混合/计算、不分区等分门别类地处理。

由于PantherLake全新架构将性能核、能效核、低功耗能效核集成在一个计算模块内,针对不同负载的调用更高效也更灵活。例如轻办公应用,低功耗能效核就能够应对,偶尔会调用性能核、能效核;有影像创作等负载需求时,则会进一步调用性能核;针对更高负载的情况,则会“不分区”全部投入使用,来发挥多线程性能优势。
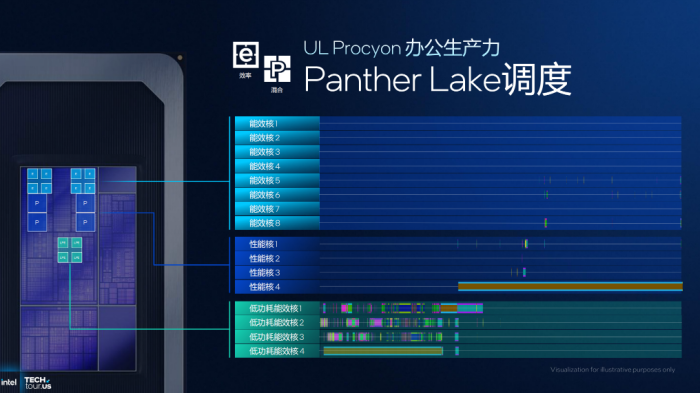
还有游戏场景下,根据负载的差异,硬件线程调度器可以让低功耗能效核“休息”,交由能效核,特别是更高性能的性能核来满足计算需求,这样既能保障CPU不会成为性能瓶颈,还可以降低功耗,让GPU充分发挥。凭借对于调度机制的优化,PantherLake可以带来10%左右的游戏性能提升。
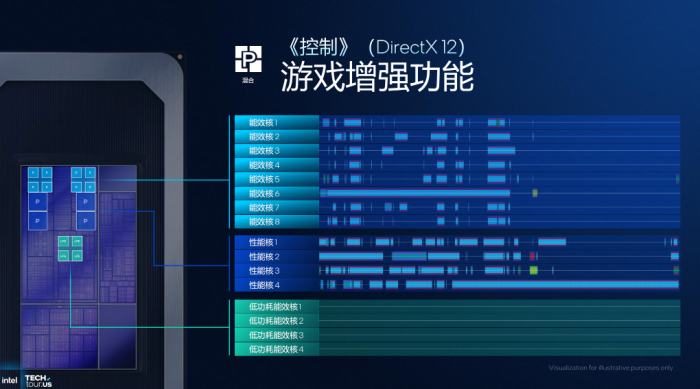
在夯实底层基础的同时,英特尔长期以来还有一项优势就是完善的软件布局,让平台与使用场景、用户需求深度融合,更好地把性能转化为生产力、用户体验。
刚刚提到的CPU灵活可扩展、硬件线程调度器等特性,让OEM可以根据对产品的理解和定位来选择对应的性能释放,这个其实大家也很熟悉就是笔记本厂商自定义的各种性能模式、增强模式、静音模式、均衡模式。在软硬件协同方面,英特尔还做了一件事——提供统一性能和电源管理堆栈,支持OEM根据自身的需求来灵活调整。

介绍一个关键特性——英特尔智能体验优化器(IntelligentExperienceOptimizer),其优势在于“省心的自动挡”。当系统处在平衡模式下,特别是离电场景中,英特尔智能体验优化器支持的智能自适应机制可以在后台根据实时工作负载,自动在预设的性能模式和更高效的节能模式之间进行无缝切换,无需手动调整。
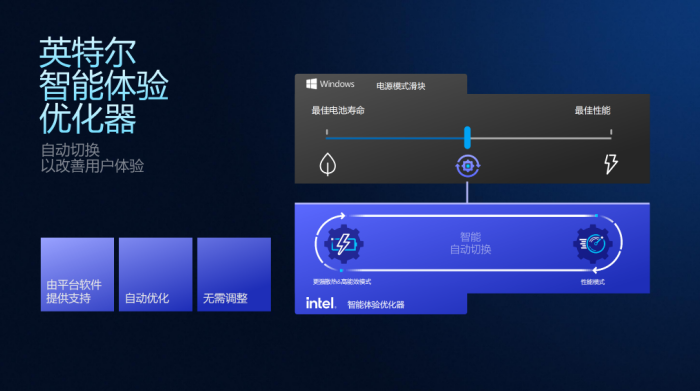
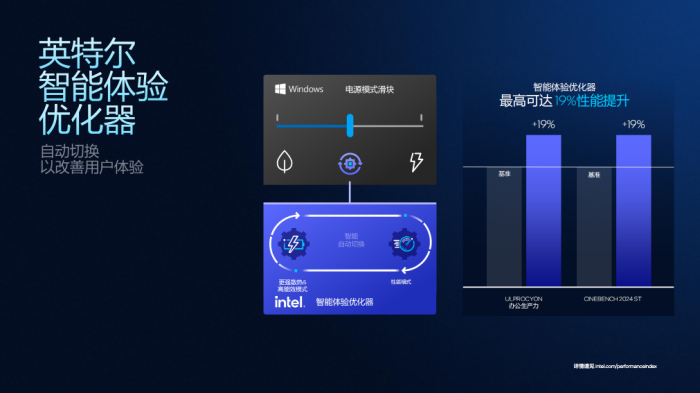
并且,英特尔表示英特尔智能体验优化器为系统内置,不依赖于特定的操作系统版本或外部IP。只要是搭载PantherLakeSoC的设备,在选择平衡模式时,均可享受到系统根据实时负载智能调配性能与能效。根据英特尔公布的测试成绩,在CineBench2024单线程性能测试、ULProcyon办公生产力测试中,英特尔智能体验优化器能够带来最高19%的性能提升。
从MeteorLake开始,核显就是英特尔面向笔记本等移动市场的一个重要亮点,无论是让轻薄本打游戏还是支持本地端AI体验,都发挥了重要作用。这次,PantherLake首发了全新Xe3架构核显,归属于锐炫B系列(顺便提一下,根据英特尔公布的路线图,下一代锐炫系列核显将采用Xe3P架构,提供更高性能、更低功耗),在性能提升的同时还带来了全新特性。

英特尔表示,Xe3架构的设计目标是提升架构可扩展性、优化性能,将Xe2图形架构与AI功能扩展至更多设备。

Xe3架构核显采用了第三代Xe核心,拥有更强的光线追踪单元、更高利用率的Xe矢量引擎、优化的图形专用硬件管线。

第三代Xe核心架构变化不大,提供8个512位XVE矢量引擎和8个2048位XMX引擎,均有增强;共享一级缓存容量也提升了三分之一,达到342KB。其中矢量引擎的线%,添加了可变寄存器分配、原生支持FP8反量化、SIMD16原生ALU、三路并发、扩展数据指令集与FP64,以及Xe矩阵扩展,由此带来使用效率提升,支持更多负载。
光线追踪单元方面,支持异步光线追踪的动态光线管理,凭借高效调度器设计,能在拥塞(光线过多导致硬件单元无法及时处理时)即将到来时降低光线分发频率,大幅提升光线追踪负载下的性能。
更优的固定功能管线拥有全新的URB管理器,可最高可支持2倍的异向性过滤、模板测试速率最高提升2倍。

每个关键硬件和引擎的性能提升让Xe3全面优化。在Xe3的每个渲染切片中,英特尔将原本的4个Xe核心提升到了最多6个,并可搭配6个光追单元。且PantherLake的GPU提供两种规格:入门级的4XeGPU,以及性能最强、规模最大的12XeGPU,可为更高负载与AI应用提供支撑。


“满血”的12XeGPU同样拥有2个渲染切片,但每个渲染切片拥有多达6个Xe核心,因此共包含12个Xe核心、96个XMX引擎、16MBL2缓存、2个几何管线个光线个像素后端。
支持多帧生成功能(XeSS-MFG)。英特尔表示,利用英特尔独有的XeSS技术做到屏幕上所有像素均可通过AI生成,提升渲染速度并且通过XeSS超分辨率技术、XeSS插帧技术、Xe低延迟技术来保证开启后顺畅体验。到了Xe3支持的多帧生成功能可以在帧与帧之间生成多帧(最多4帧),来提供更高的帧率。
从AIPC概念确立以来,相比CPU、GPU,NPU的定位就有些许“尴尬”。尽管针对AI负载有高能效等优势,但是ISV围绕NPU来优化或打造应用却是一个难点。不过英特尔已经发现,目前在执行AI负载时,NPU的利用率正在快速提升。为了让NPU惠及更多AIPC,英特尔在保持架构一致性的前提下进一步优化了效率。因此,
NPU5拥有最高50TOPS的算力。不过值得关注的是针对AI应用,英特持续发局CPU、GPU、NPU组成的XPU异构计算能力,且为不同负载匹配更高效的算力。全新PantherLake的平台AI算力最高能够达到180TOPS,其中CPU最高10TOPS,GPU最高120TOPS。

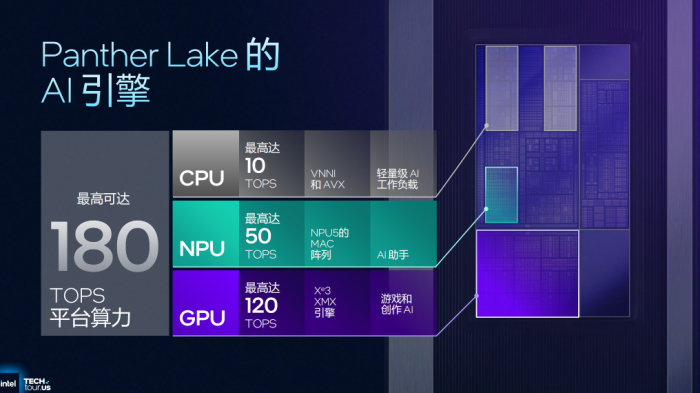
针对当前及未来AI应用场景,英特尔也分享两个重要的PC端AI应用,一个是刚刚提到的多帧生成功能(XeSS-MFG),另一个则是整个AI行业备受关注的“AI智能体”。有关AI智能体的概念就不过多赘述了,目前包括PC、手机等更多终端均在围绕AI智能体挖掘创新点。
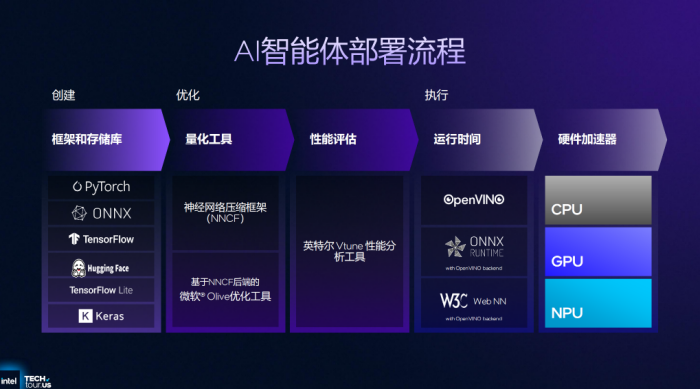

相比于云端,能够在终端侧部署的AI智能体不仅可以满足用户对于个性化、定制化的追求,同时也能更好地保护数据隐私安全,毕竟智能体想要“好用”还是需要足够的用户数据作为支撑。就目前而言,AIPC的AI应用正在快速发展,这与AI智能体的发展也相呼应,只不过想要真正达到预期,还需要英特尔与OEM、ISV等软硬件合作伙伴持续推动。

Wi-Fi7R2主要提升了网络性能、可靠性和能效,包括多连接重配置、受限TWT(目标唤醒时间)、单链接eMLSR(增强多连接单射频)、P2P通道协调、MIMO增强、混合自动重复请求(HARQ)、低延迟操作等。与Wi-Fi6相比,英特尔Wi-Fi7能够提升连接性能、可靠性、安全性,并降低延迟。

蓝牙6.0支持蓝牙信道探测、基于决策的广播过滤、监视广播设备、ISOAL(等时适配层)增强、LL扩展功能组、帧间隔更新等新特性,还有更好的蓝牙LE音频,比如Auracast广播能力。PantherLake还支持双蓝牙,通过在一个模块里集成两个蓝牙核心,实现性能翻倍,大幅提升速率、通信距离。

ICPS5.0具备三大功能:高级蓝牙监控、通过AI感知服务质量的QoS、增强型的流量优先级。

第一,支持系统共享内存,实现无限分辨率的高级时域处理。第二,IPU可以直接访问用于高级AI处理的CPU、GPU、NPU等计算引擎。
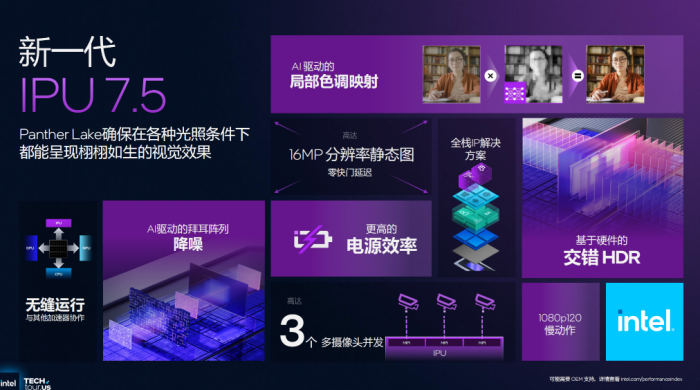
值得一提的是,IPU并非PantherLake中首次采用,从2014年推出第一代IPU至今,已经迭代到了IPU7.5,能够有更高能效,支持最多3个摄像头并发、1080P120Hz慢动作,同时为PantherLake带来了增强型HDR、AI降噪以及AI驱动局部色调映射三项创新特性。让用户在视频通话、直播等调用笔记本摄像头场景下,有更好的画面呈现。
双重曝光交错HDR:可以让影像有更宽的动态范围,以IPU将长短曝光的图片组合,从而保证亮部和暗部都有更真实的细节。得益于硬件加速,HDR处理过程很快,支持4K分辨率、自适应曝光控制、各种传感器,且功耗降低了1.5W,也能在一定程度上缓解视频通话耗电快的痛点。

AI降噪:得益于集成IPU设计,PantherLake可由GPU、NPU结合AI算法为影像降噪,能够支持高达5MP传感器、更高的帧速率和清晰度,有效提升弱光下的图像与视频表现,让镜头小型化设计的相机成为可能。
AI驱动局部色调映射:支持AI驱动的参数调节,可改善照片的对比度,无光晕伪影,无色彩伪影,保持时域行为一致性,呈现更逼真的成像效果。

另外,英特尔还提供了硬件、OEM参考设计、驱动(包括IPU驱动、传感器驱动、闪存驱动)等完整的IPU软件和硬件堆栈,以及动态库,让整个解决方案可以支持Windows,谷歌的Chrome和Linux操作系统。此外还有完整的软件开发包,包括摄像头的开发模块,更容易在英特尔平台上实现校准和色彩的调校。
从英特尔公布的架构创新来看,在Intel18A制程工艺加持下,PantherLake在能效、性能、可扩展性方面都有值得期待的亮点。CPU拥有全新性能核、能效核,以及低功耗能效核,组合硬件线程调度器与软硬件协同优化,做到了兼顾性能与能效,虽然与LunarLake的封装设计有所不同,但对于下一代笔记本的续航和生产力,还是让人有了更多期待。
GPU方面也是PantherLake的一大亮点,全新Xe3架构及灵活的可扩展性,让PantherLake有更丰富的SKU,从超轻薄本到全能本,或许用户能从中选择更适合自己的产品,面对工作、娱乐、创作等复杂应用场景有更出色的体验。毕竟,12个Xe核心带来的核显性能,应该能让“轻薄本打游戏”更加顺畅。

至于NPU,尽管也在能效方面有进步,但更让笔者期待的还是英特尔XPU计算架构下PantherLake高达180TOPS的总算力能够创造哪些新体验。英特尔在2026年将如何与OEM、ISV进一步合作,充分发挥CPU、GPU、NPU的优势,让AI包括智能体成为可用、易用、好用的生产力工具,转化为提升用户体验的发力点。
